Welcome to the GlobDB genomes database
This website hosts the GlobDB, a dereplicated set of species representative microbial genomes. The current release is GlobDB release 232
The genomic era offers great opportunities for microbial genome analyses, and individual (meta)genome studies can generate thousands of microbial genomes. Although the International Nucleotide Sequence Database Collaboration (INSDC) databases are available to store these datasets, depositing assembled and binned metagenome assembled genomes (MAGs) to INSDC databases doesn't always happen. The GlobDB aims to integrate 26 genome resources (see citations for a complete list) that are currently not (yet) consolidated otherwise.
Our paper describing the GlobDB has been published in Bioinformatics Advances.
For the latest news and updates related to the GlobDB and the AASTK, see the News page.
GlobDB features
The 26 genome resources (see below) provide either "species dereplicated" genome catalogs or are dereplicated before they are added to the dataset (see Methods). These catalogs are then further dereplicated against each other, and finally the GTDB, and the dereplicated set is processed in a standardised way to yield a comprehensive dataset that can be used for further analyses. Currently, the GlobDB comprises 346,233 (partial) microbial genomes after dereplication of the 26 source datasets.
For all 346,233 genomes, the GlobDB features:
- Genome fasta files with standardized names and IDs
- Anvi'o contigs databases, annotated with KEGG/COG/Pfam/dbCAN2
- Amino acid fasta files with standardized identifiers
- GFF files for coordinates of genes
- A full 7-level taxonomy built upon and extending the GTDB taxonomy
- Basic genome statistics and completeness/contamination
Furthermore, the GlobDB includes:
- a SingleM metapackage linked to the GlobDB taxonomy, for taxonomic profiling of metagenome datasets
- a Sylph database linked to the GlobDB taxonomy, for taxonomic profiling of metagenome datasets.
A schematic overview for the GlobDB (for release 226) is shown below
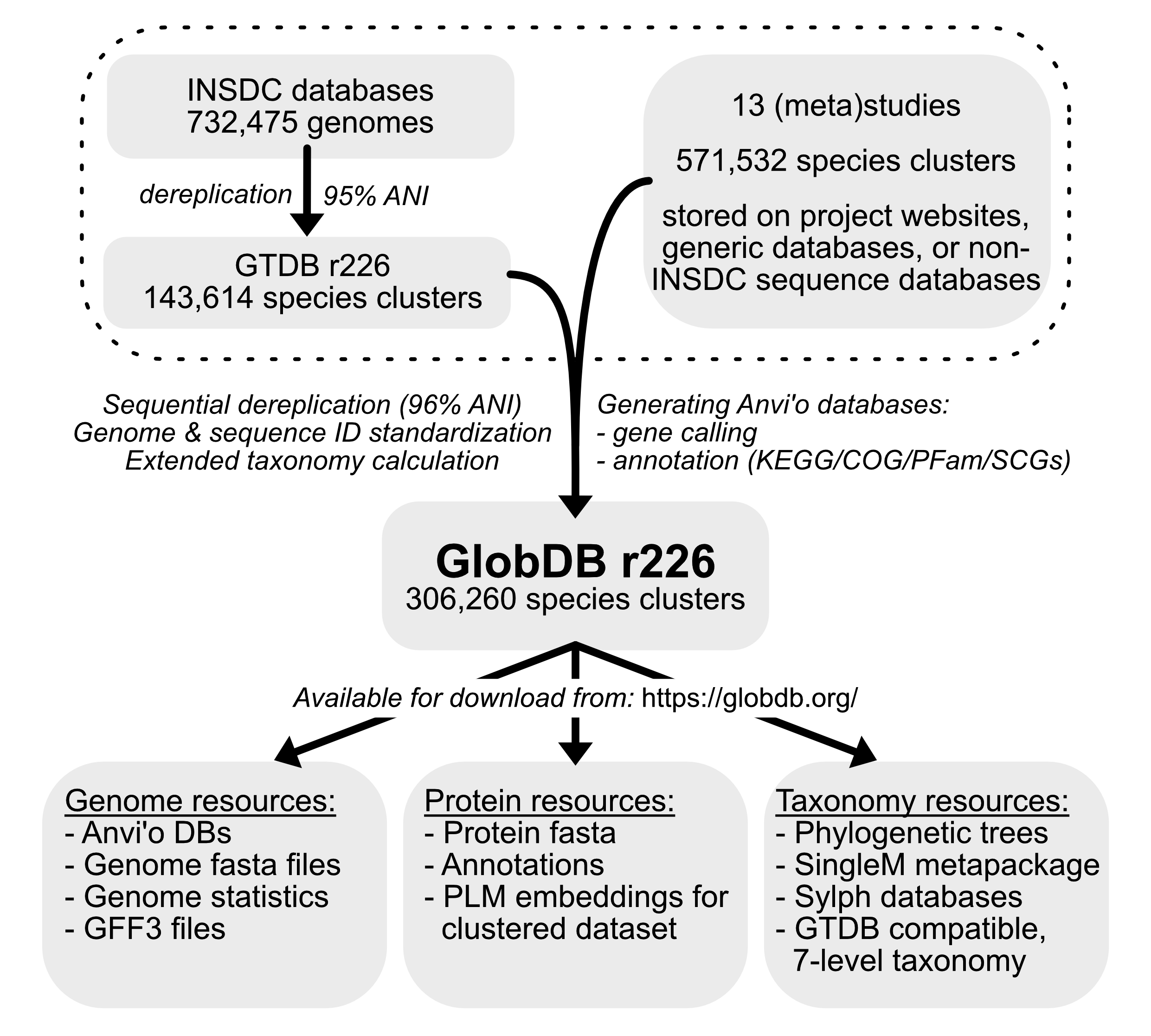
See the Methods for details on data processing, and Downloads for a description of available files. The source datasets for the GlobDB are listed on the Citations page.
If you use the GlobDB, make sure to cite the underlying data sources and methods as appropriate, see How to cite.
Updates, versions, maintenance
The current GlobDB version is 232. The GlobDB follows the GTDB update schedule, which is currently once per year. The version numbering is linked to GTDB, which is in turn taken from to the NCBI RefSeq versioning.
The GlobDB is maintained by Daan Speth, senior scientist at the centre for microbiology and environmental systems science (CeMESS) at the university of Vienna, with contributions from colleagues at CeMESS and the centre for microbiome research at the Queensland University of Technology (QUT). See contributors for more information.
The GlobDB is hosted on the life science compute cluster (LiSC) of the University of Vienna. For any questions related to the GlobDB, please contact Daan Speth
License
the GlobDB propagates the licenses of the underlying data sources, and is licensed under CC BY-SA 4.0.
This means you are free to:
Share — copy and redistribute the material in any medium or format for any purpose, even commercially.
Adapt — remix, transform, and build upon the material for any purpose, even commercially.
Under the following terms:
Attribution — You must give appropriate credit , provide a link to the license, and indicate if changes were made . You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use.
ShareAlike — If you remix, transform, or build upon the material, you must distribute your contributions under the same license as the original.
See https://creativecommons.org/licenses/by-sa/4.0/ for full license details